

Lessons from Downloading Every Issue of an Undownloadable Magazine
Let’s say, for argument’s sake, that a beloved magazine returns from the dead. And that on their site — which has been resurrected — they’ve uploaded digital editions of the last 12 years of their print publication. These issues, most of which have never been preserved before, provide a window into North American gaming culture as it unfolded between 2012 and 2024; a valuable resource for future researchers. The new site is an unexpected and welcome reprieve for material that had been presumed lost when it was taken offline, without warning, months earlier.
We know from experience that the future of publications like these is never guaranteed, and that there’s a certainty that — whether in one, five or twenty years — the site will eventually disappear. When that happens, it would sure be hypothetically nice if we had local PDF copies of all 140 digital issues, which — combined with Retromags’ scanned versions of everything up to 2015 — would constitute, as of the time of writing, a fully preserved run of every single issue from the magazine’s 33-year history.
Unfortunately, this site (for the sake of brevity, let’s call it, I dunno, Gaming Pharma) has no ‘download PDF’ button. Which means I’m going to have to do it the hard way.
I hadn’t worked on a project similar to this before, and though I expect a veteran of content ripping could have breezed through it in a few hours, I jumped in blind and figured it out over a few days.
This is not a tutorial for downloading magazines, and please don’t ask for one. It’s just a record of some of the problems I hit along the way.
The publication in question is, right now, trying to build a viable business model, and the back issues are a part of that, so please visit their site and register for access. Should the worst happen, these issues are preserved. But the team was given a rare second chance, and once there’s an opportunity to help keep the publication financially viable, I would urge you to do so.
It seemed relatively straightforward to figure out, using Firefox’s web inspector, how the magazines were delivered to the browser, and I scripted up some Python to download each issue’s files to a local folder. But straightforward to download doesn’t mean easy to handle.
Each page of each magazine was delivered to the browser as both a raster image (depending on zoom level, either a JPG or one of several WEBMs of different sizes) and as an SVG file containing the page’s text and typography, zoomable without loss of fidelity. These two images were overlayed in the browser by the JavaScript viewer, and further pages were downloaded on the fly as they were accessed. To cut to the chase, this was nowhere near as simple as a PDF sitting on a server. If PDF’s the goal, I’d have to build them from scratch.
Problem 1: How to convert SVG to PDF?
The first hurdle was more difficult than I expected. There are many ways to convert an SVG file to a PDF in Python or at the command line, and I tried all I could find. Some (like ImageMagick) rasterise the vectors, losing fidelity and the original searchable text. Almost every method I tried substituted the custom fonts in the SVG for default fonts, meaning text no longer fit inside its bounding boxes and rendering the page ugly at best and unreadable at worst. Even Adobe Illustrator — which would have been my first guess at a tool that might have worked — made a royal mess of it:

Then I stumbled upon Gapplin, a free SVG viewer for macOS. It had a PDF export function, which — crucially — preserved typography and kept the text in the SVG file searchable in the output PDF. Nothing was lost in the conversion. It was the exact tool I needed.
I ended up building an Automator action that called this application to batch-convert a set of downloaded SVG files to individual PDFs. This introduced an intermediate manual step in the download and conversion process, which wasn’t ideal, but since I had to manually grab URLs and parameters for each issue anyway I resigned myself to the fact that the workflow would require active participation.
Problem 2: What about the pages with no SVG files?
Early in the process I realised that pages with no text on them didn’t have a blank SVG file on the server; the SVG file didn’t even exist. But the assembly process needed an SVG to convert to a PDF per page. “Easy”, I thought, naively. “If there isn’t one on the server, I’ll just print a bare bones SVG document to a file handle and create one.”
Some time later, I realised that not every magazine had the same page dimensions, and the blank SVG document I was writing identically every time, that I’d based on a single page of a single issue, was the wrong size for others. This meant that the merged file had differing page sizes in the same PDF: still readable, but far from ideal. I had to rewrite my script so that the blank pages were assigned dimensions that had been pulled from the other SVG files for that particular issue. This was the first time — after fixing that bug — that I had to redownload and rederive a bunch of files. Unfortunately, it wasn't the last.
Problem 3: What am I supposed to do with all these files?
Okay. Now I had a folder of single PDF pages, converted from SVG, each of which contained the text (vectorised and searchable), but none of the images. They looked something like this:

And a separate image per page that included only the graphic elements, which looked something like this:
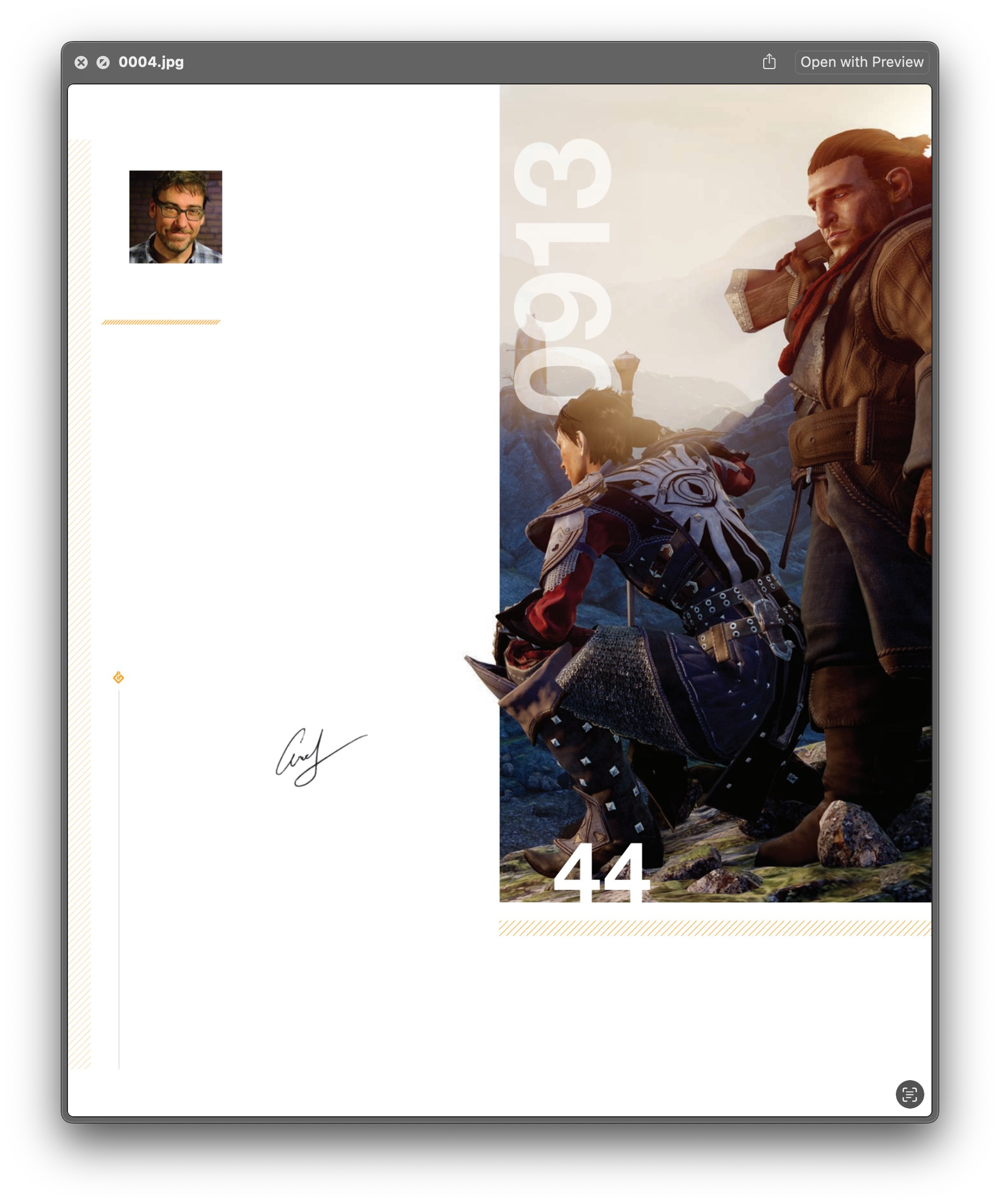
I needed to add that graphic to that PDF, but didn't want the graphics to obscure the text where they shared space; how to add the raster layer behind the text? It turns out that this is fairly easy to do: it's exactly the same thing as adding a full-page watermark, and that’s a common operation.
It was at this point that another user on the Gaming Alexandria Discord did me a big favour, and pointed out that the highest-quality WEBM files I was pulling from the server (and converting to PNG, because PDF doesn't support WEBM images) were inferior in resolution to a JPEG option. (Thanks to Bestest for that crucial tip.) I’d overlooked the existence of those files as they were only delivered to the browser at the highest zoom levels; switching to the JPEGs gave better quality at much smaller file sizes. After a little experimentation, I was satisfied that these files were as good as it got.
For the second time, I redownloaded and rederived a bunch of files.
Problem 4: Wait, why is there still text missing?
Feeling good about resolving those problems, and confident that I was downloading at the best available quality, I started the full download run, laboriously performing the steps required for each issue. Around fifty issues in, I noticed something wrong. As PDFs were being merged, and as I flipped through them in a PDF viewer, occasionally a page appeared with obviously missing text — text that was present on the web version.
I initially assumed that the SVG downloads must be sporadically failing, but adding a retry loop made no difference. They were 404ing reliably on pages that definitely had text; this was something new.
After further investigation (and getting, honestly, a little fed up with the whole thing at this point), I discovered that in the occasional case — only on a few issues, and only on a few pages in those issues — the text on the page wasn’t being delivered as vectorised SVG, it was being delivered as rasterised transparent PNG, a format I’d never seen show up in the inspector panel and therefore hadn’t been downloading or checking for.
I realised that my assumption that text on a page would always be SVG wasn’t true. Though that was the case for 95%+ of pages, the reality was that the text layer could be either SVG or transparent PNG… and that an unknown number of issues I’d already downloaded were affected by this oversight.
After implementing a fix, I deleted all of the output files and started again, fortunately for the third and final time.
Overall, figuring out how to grab and convert these magazines, scripting the code to do it, and going through the tedious process of running 140 issues through the workflow one by one, with several false starts, took me about ten days. From initially poking around with it to being in possession of a complete set of downloads, I’d guess that I put somewhere between 10 and 20 hours into the project. It’s possible there are others who’ve done the same thing, but it’s also quite possible that I’m the only one to have accomplished it; I’ve absolutely no idea. But I had an itch, I figured out how to scratch it, and it worked out.
The resulting PDFs of Gaming Pharma are on my NAS, backed up with two different cloud providers, and have been entrusted to several archivists for safekeeping. Though they’re not publicly accessible, they are not at risk. Should the magazine in question suffer closure for a second time and the site become inaccessible, all 140 issues will be uploaded to the Internet Archive.

